
KubeSpray, installer kubernetes et créer un utilisateur admin en quelques minutes
Si vous voulez vous mettre à Kubernetes, sur des machines physiques ou virtuelles, il serait bon de lire ce petit article pour ne pas vous trouver en état de panique après quelques minutes. Essayons de faire les choses simplement.
Kubernetes (développé par Google) est un orchestrateur de conteneurs qui permet une maitrise poussée du fonctionnement. Il fonctionne presque partout, apporte une normalisation des déploiements, une gestion des rôles poussés, etc… Google a vraiment bien faut le boulot et a proposé cet outil sous licence libre.
Red Hat a d’ailleurs refondu OpenShift en surcouche de la solution, ce qui induit que si vous comprennez Kubernetes alors OpenShift vous semblera très familier après coup. Les objets Kubernetes sont d’ailleurs utilisables dans OpenShift.
Bref, l’installation de Kubernetes est un sujet qui peut s’avérer un peu compliqué si on s’y prend mal, alors que la réalité est toute autre. Nous allons utiliser un projet nommé “kubespary” qui utilise Ansible pour le provionnement de machine.
Ensuite, on passera au paramètrage de notre client “kubectl” pour arriver à utiliser le dashboard depuis notre ordinateur.
Préparation de l’environnemnt
- Il vous faut 3 machines (VMs, ou phyique) sur lesquelles vous pouvez vous connecter en ssh avec une paire de clefs.
- Il vous faut Ansible version 2.4 (c’est ce que j’ai, ça marche peut-être avec une version antérieure).
- Et on aura besoin de kubectl sur le poste client
- Et enfin, il faut la commande “pip” (paquet python-pip sur Fedora) et que votre PATH ait “~/.local/bin”.
Faites en sorte que le répertoire ~/.local/bin soit dans votre PATH, ce sera plus simple…
Téléchargement de kubectl
Là c’est simple:
$ curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
$ chmod +x kubectl
$ mv kubectl ~/.local/bin
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"8", GitVersion:"v1.8.4", GitCommit:"9befc2b8928a9426501d3bf62f72849d5cbcd5a3", GitTreeState:"clean", BuildDate:"2017-11-20T05:28:34Z", GoVersion:"go1.8.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"8", GitVersion:"v1.8.3+coreos.0", GitCommit:"f96beb2e925b0bb4e6ac0de746c7155dcd8fdc10", GitTreeState:"clean", BuildDate:"2017-11-13T10:18:37Z", GoVersion:"go1.8.3", Compiler:"gc", Platform:"linux/amd64"
Un truc pratique à savoir, kubectl permet la completion dans Bash, ce que vous pouvez faire c’est d’ajouter la commande suivante dans votre fichier ~/.bashrc:
source <(kubectl completion bash)
Vous pouvez aussi taper cette commande dans votre session bash actuelle por l’activer de suite.
Installation de kubspray
Le projet est sur la page github: https://github.com/kubespray/kubespray-cli
On commence par installer kubespray-cli - je préfère toujours utiliser “pip” en mode “user” pour que l’installation soit dans mon “home” (holalal que du franglais). C’est simplement que n’aime pas que mon utilisateur installe des trucs qui ne sont pas la distribution Linux que j’utilise, ailleurs dans le système. Et “pip” sait faire ça:
pip install --user kubespray
Si vous avez bien ~/.local/bin dans votre “PATH”, tout va bien se passer.
Maintenant, on va créer un inventaire Ansible. Vous pouvez le faire manuellement mais kubespray sait le créer pour vous:
kubespray-cli prepare --nodes node1 node2 node3
Vérifiez ensuite l’inventaire que vous allez certainement vouloir modifier. Il se trouve à l’emplacement ~/.kubespray/inventory/inventory.cfg
Voici le mien:
[kube-master]
origin-m1
origin-m2
origin-m3
[all:vars]
ansible_user=root
[all]
origin-m1
origin-m2
origin-m3
[k8s-cluster:children]
kube-node
kube-master
[kube-node]
origin-m1
origin-m2
origin-m3
[etcd]
origin-m1
origin-m2
origin-m3
Ici, j’ai donc 3 machines qui sont toutes master, node et noeud etcd.
J’ai ajouté la partie “[all:vars]” pour forcer l’utilsateur (root, c’est mal…), et notez aussi que vous pouvez ajouter des variables à chaque noeud du groupe “all” pour, par exemple, donner l’adresse IP de la machine cible (eg. origin-m1 ansible_ssh_host=xx.xx.xx.xx).
Bref, il faut quand même respecter deux ou trois choses:
- etcd doit avoir 3 machines, c’est nécessaire pour le concensus
- avoir au moins un node et un master
- de l’aspirine si ça marche pas
On teste si tout est ok:
$ ansible -i ~/.kubespray/inventory/inventory.cfg all -m ping
origin-m2 | SUCCESS => {
"changed": false,
"ping": "pong"
}
origin-m1 | SUCCESS => {
"changed": false,
"ping": "pong"
}
origin-m3 | SUCCESS => {
"changed": false,
"ping": "pong"
}
Toutes les machines doivent répondre par un pong. Si c’est pas le cas:
- vérifiez les hosts
- vérifier l’utilisateur
- avez vous bien envoyez vos clefs aux serveurs ?
- etc…
Provisionnement des machines
Bon, on passe à l’installation:
$ kubespray deploy
# [...]
PLAY [lb] **************************************************************************************************************
skipping: no hosts matched
PLAY RECAP *************************************************************************************************************
xxx : ok=64 changed=19 unreachable=0 failed=0
yyy : ok=64 changed=19 unreachable=0 failed=0
zzz : ok=64 changed=19 unreachable=0 failed=0
C’est parti. l’installation prend entre 10 et 20 minutes environ selon le nombre de machines, la puissance de votre ordinateur, la phase de la lune et le cours de rouble.
Si tout est “ok” à la fin, bravo.
Chez moi ça a pété… j’ai relancé l’installation et cette fois tout est rentré dans l’ordre. Pour info, de mon coté, j’avais une perte de connexion entre un node et un master. Impossible de savoir pourquoi.
Alors oui, j’ai omis le fait que vous pouvez modifier plein d’options, comme le type d’overlay network, ou les CIDR à utiliser. Là je vous la fait simple.
Maintenant, il faut qu’on puisse se connecter au cluster pour le paramétrer. Et là… ça devient moins marrant.
Paramétrer un utilisateur
Si vous connaissez bien OpenShift, vous savez que l’on a le moyen de s’authentifier directement sur la plateforme, comme ça, en allant sur la “console web”. Mais sur Kuberentes c’est un poil plus compliqué. Car Kubernetes est légèrement plus bas niveau que OpenShift (rien de péjoratif).
On va donc faire en sorte que depuis votre PC vous puissiez vous connecter à votre cluster.
La méthode que je choisi est la méthode “certificat client”. Je la trouve plus sécurisée et surtout plus claire.
On va donc devoir créer une clef privée, puis une demande de signature (CSR), envoyer ce CSR à un master, signer la requête et récupérer le certificat.

Comme la version de Kubernetes actuelle est >= 1.8 on va se confronter au “role binding”, en gros c’est le fait que votre utilisateur a un certains nombre de droits associés. Là, on va carrément créer un admin.
Génération de clefs
On commence par créer un répertoire où on va stocker notre clef privée, le CSR, et le certificat signé. Puis on génère la clef privée.
# on crée un répertoire de config
mkdir -p ~/.config/kubernetes/
# Choisissez un pseudo, et mettez le dans _username
_username="votre pseudo"
_organisation="toto.com"
# clef privé à ne faire qu'une fois
openssl genrsa -out ${_username}.key 2048
Création d’un CSR
Vous avez donc ici une clef privée “votre_user.key”, créons une requête de signature (CRS = Certificate Signing Request):
openssl req -new \
-key ${_username}.key \
-out ${_username}.csr \
-subj "/CN=${_username}/O=${_organisation}"
Ce qui compte ici, c’est surtout l’entrée “CN” (Common Name) qui correspondra à votre nom d’utilisateur.
Génération du certificat
Voilà, vous avez un “CSR”, on le dépose sur un des masters et on va créer le certificat associé à la demande. Pour cela il faut utiliser le certificat de l’autorité (le cluster kubernetes) et la clef privée de cette autorité. On va créer un certificat valable 1 an:
scp ${_username}.csr root@votre_master1:/tmp/${_username}.csr
ssh root@votre_master1 openssl x509 -req \
-in /tmp/${_username}.csr \
-CA /etc/kubernetes/ssl/ca.pem \
-CAkey /etc/kubernetes/ssl/ca-key.pem \
-CAcreateserial \
-out /tmp/${_username}.crt \
-days 365
Nous avons créé le certificat “votre_user.crt” sur le serveur maitre, on va le récupérer sur notre machine.
scp root@votre_master1:/tmp/${_username}.crt ~/.config/kubernetes/${_username}.crt
Configuration de kubectl
On fait le bilan:
- on a une clef privé “votre_user.key”
- un certificat signé par le serveur “votre_user.crt”
- le tout dans ~/.config/kubernetes
On va maintenant paramétrer kubectl pour les utiliser.
Il faut:
- créer une config de serveur (un cluster): indiquer quel machine on va interroger
- créer un user en se basant sur la clef et le certig
- créer un “contexte” qui rassemble cet user et ce “cluster”
Ces commandes font le boulot:
# création d'un config de cluster
kubectl config set-cluster NOM_DU_CLUSTER \
--server=https://ip.du.master:6443 \
--insecure-skip-tls-verify=true
# création d'un utilisateur utilisant des certif
kubectl config set-credentials ${_username} \
--client-certificate=~/.config/kubernetes/${_username}.crt \
--client-key=~/.config/kubernetes/${_username}.key
# on lie le cluster à un utilisateur
kubectl config set-context NOM_DU_CONTEXXT \
--cluster=NOM_DU_CLUSTER \
--user=${_username}
N’oubliez pas de changer les noms de cluster et de contexte avec un truc dont vous vous souviendrez.
Bon, voilà, on peut utiliser ce context:
kubectl config use-context NOM_DU_CONTEXXT
Et là, le drame:
kubectl get nodes
# ERROR, pas les droits
Et oui, votre utilisateur n’est pas dans les petits papiers de Kubernetes, il n’a pas de droits associés. On va remédier à ça.
Donner les droits “admin” à cet utilisateur
Il existe deux “binding” de droits, les RoleBinding sont utililsés pour les namespaces, et les ClusterRoleBinding pour les droits du cluster entier. Ici, nous voulons donner un droit à un utilisateur sur tout le cluster.
Si vous tapez “kubectl get clusterrolebinding” vous verrez une liste conséquente d’associations de droits possibles. Celui qui nous intéresse est le binding “cluster-admin”:
Allez sur un master (via ssh), et faites simplement:
# si vous n'aimez pas vi, tapez EDITOR=nano
# par exemple, avant cette commande
kubectl edit clusterrolebinding cluster-admin
Cela va ouvrir un éditeur “vi”, ajoutez dans “subjects” votre utilisateur:
#...
subjects:
# ...
- apiGroup: rbac.authorization.k8s.io
kind: User
name: nom_de_votre_user
Sauvez, et revenez sur votre machine à vous. Relancez:
$ kubectl get nodes
NAME STATUS AGE
origin-m1 Ready X
origin-m2 Ready X
origin-m3 Ready X
Et voilà !
Evidemment, on est pas forcé d’ajouter l’utilisateur en admin, un “rolebinding” simple peut donner des droits à un utilisateur sur un namespacce en particulier, et il pourra au choix avoir le droit d’écriture, de lecture, etc…
Voir la page: https://kubernetes.io/docs/admin/authorization/rbac/
On résume
Ça parait bourrin et lourd, mais c’est en fait super simple quand on résume:
- on crée une clef privée SSL
- on crée une demande de signature de certif
- on envoit ça à un serveur “master”
- le master signe le certificat
- on le récupère sur le pc
Ensuite:
- on crée une config de cluster sur le client pour indiquer où se trouve le ou les masters
- on crée une config utilisateur sur le client pour dire quelle clef et quel certif utiliser
- on lie les deux dans un “context” (un utilisateur + un cluster)
Et enfin:
- on ajoute des droits à l’utilisateur sur le cluster (admin ou autre)
Ouvrir le dahsboard
On va maintenant utiliser kubectl pour avoir le dashboard. La méthode que je recommande est d’utiliser kubectl en mode “proxy”, cela permet de ne pas laisser le dashboard entre toutes les mains et de ne pas avoir à paramétrer le navigateur pour accepter certains certificats.
$ kubectl proxy
Starting to serve on 127.0.0.1:8001
Ouvrez la page http://127.0.0.1:8001/ui et admirrez votre dashboard. Halalala ça fait plaisirs non ?
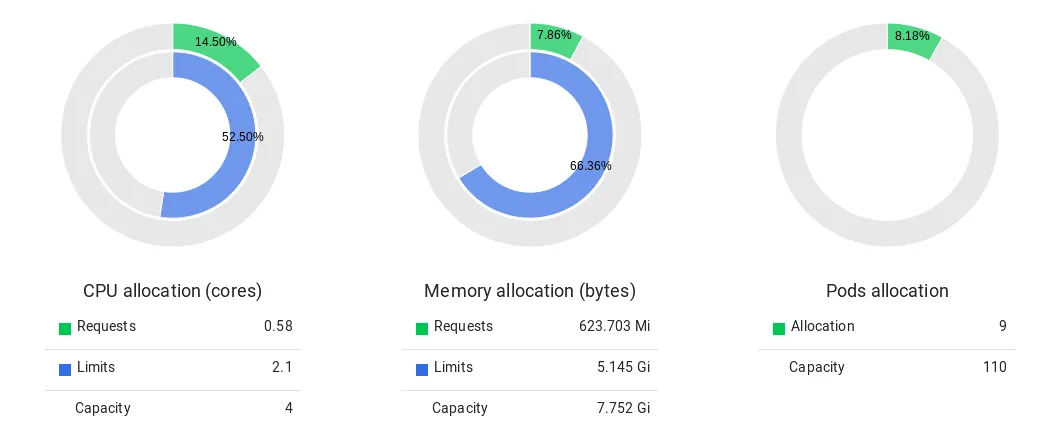
En bref
Si vous venez de version inférieures à 1.8 de Kubernetes, les RBAC (Role-Based Access Control) vont vous dérouter un petit peu en premier lieu. Ceux qui viennent du monde OpenShift ont déjà pas mal travaillé avec la gestion de rôles ce qui leur donne un petit avantage.
Cela-dit, kubespray est un outil super sympa depuis que le projet kubernetes-ansible n’esst plus supporté (devenu obsolète en faveur de kubespray) et je n’ai vraiment pas mis longtemps à adapter mes inventaires pour générer un cluster sur ScaleWay - j’ai encore des soucis avec GlusterFS et Heketi sur Scaleway dont les admin ont l’air de se foutre du fait que nous avons besoin de SELinux (ce qui m’a coincé pour OpenShift) malgré nos relances en ticket de support et sur l’issue Github https://github.com/scaleway/image-centos/issues/19
Mais bon, avec un peu de lecture et quelques tests, j’ai un cluster qui fonctionne en moins d’une heure avec Heapster, Traefik etc…
Reste helm qui refuse de fonctionner à cette heure, mais je vais bien finir par y arriver !