
Comment J'ai Généré Un Dataset Avec L'IA

J’avais besoin d’un dataset de produits en JSON, en français, et pas moyen de trouver un truc bien sur le net (gratuitement). Alors je me suis lancé dans une folie : demander à une IA de le faire pour moi. Et localement !
EDIT: allez voir le second article, j’ai découvert “LLama.cpp” et son backend Python, je vous conseille vivement de lire mon test.
Si vous être trop pressé, allez en bas de l’article pour trouver le lien du code source. Lisez les commentaires en début de script et débrouillez-vous. Utilisez LM Studio pour lancer une API local avec un modèle Mistral 7b hein !
Non parce que bon… Payer une API OpenAI ou Mistral pour un test perso, ça m’énerve un peu. Il fallait bien que trouve une solution.
e me dis, donc, que ChatGPT 3.5, gratos, va me faire un truc pas mal. Et effectivement en lui demandant ce genre de contenu, il fait le job. Mais voilà :
- D’abord, il répond gentiment avant de me foutre un bloc Markdown. Il faudrait que je clique sur le bouton “copier”, puis aller coller ça dans un fichier. Pour 1000 produits, ça va être long…
- Et on est un peu limité par la taille de sortie
- Et puis ce n’est pas évident pour lui de garder le contexte. Il a tendance à oublier les règles de base qu’on lui a donné (parce que l’historique est limité)
- Et puis j’ai envie de m’amuser un peu.
Donc, LM Studio…
LM Studio ?
LM Studio est une interface assez bien pensée qui vous permet de jouer avec des modèles LLM (Large Language Model) sur votre PC personnel. Sans trop d’effort, et de manière très intelligente (en utilisant des modèles reformatés, et en jouant avec votre matos).
Grosse déception, ce n’est pas un logiciel open source. J’en demande beaucoup, mais j’aurai tellement préféré. Pour une fois, je fais l’impasse sur mes principes et j’accepte leur licence.
Alors, j’ai tendance à leur faire confiance. Ils garantissent ne pas récupérer de données personnelles, tout ce que vous faites reste privé, je me demande quand même comment ils gagnent leur vie…
Attention, vous devez avoir une machine récente. Que votre CPU supporte AVX2, et franchement il vous faut un GPU si vous ne voulez pas prendre des rides en attendant une réponse d’un modèle.
Bon, j’ai un laptop avec une RTX 3060, donc je pense pouvoir charger une partie du modèle dans la VRAM. Je sais que Mistral ne passe pas entièrement mais “LM Studio” utilise une méthode avec “llama cpp” qui peut scinder le modèle dans la RAM. Donc je serai en hybride “CPU/GPU” mais ça fera l’affaire.
En fait je pourrais très bien utiliser les
ctransfomersde HuggingFace, me battre pour trouver la configuration à donner au modèle et blablabla. Mais je veux faire un truc rapidement là, LM Studio est pas mal fichu, donc je me dis que pour tester…
Donc hop. On lance LM Studio, on récupère un modèle pas trop lourd, genre “mistral-7b-instruct-v0.2.Q6_K.gguf” et je me lance.
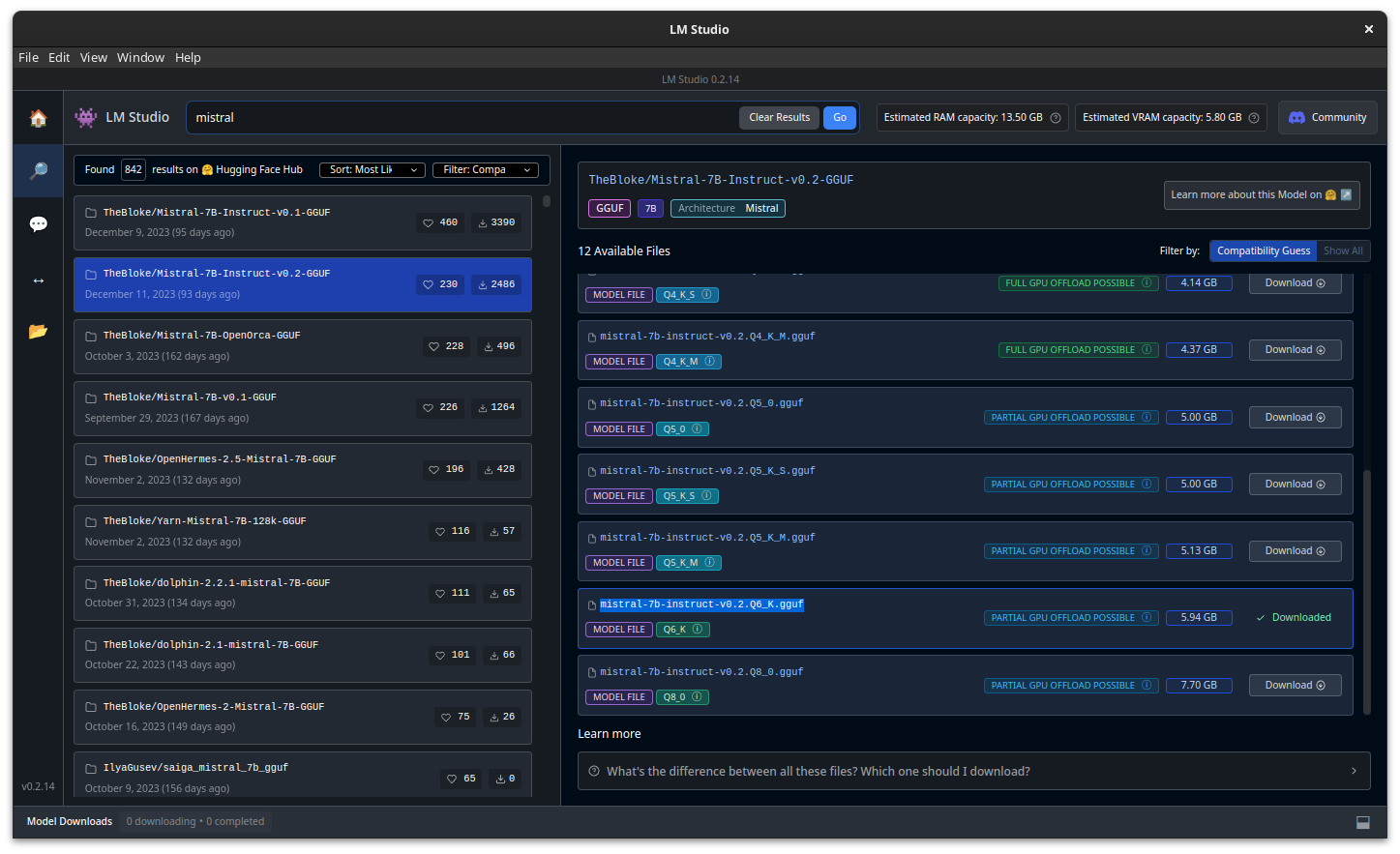
On lance un “chat” sur ce modèle, on tente des paramétrages…
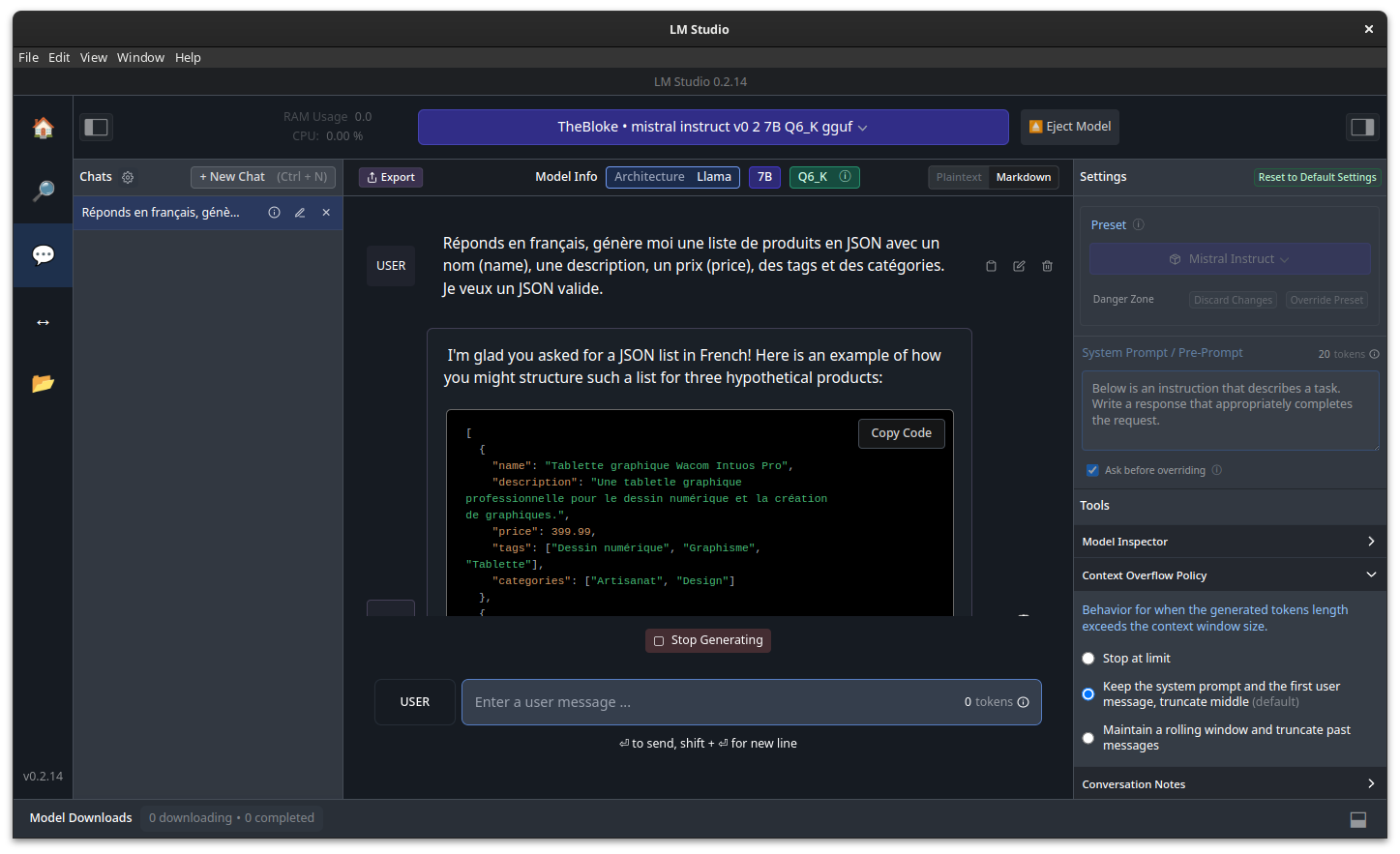
Le bot répond, c’est cool, ça marche sur ma machine… Il répond en anglais, mais les produits sont en français. On va passer ce détail et se dire “bon ça ira”.
Mais je me retrouve finalement dans la même situation qu’avec n’importe quel “Chat” que l’on trouve en ligne (HuggingChat, ChatGPT, Gemini, …) - On est sur une “interface utilisateur”, pas un truc pour générer des fichiers.
Ou pas ! Parce qu’il y avait un onglet que je n’avais pas vu !!!
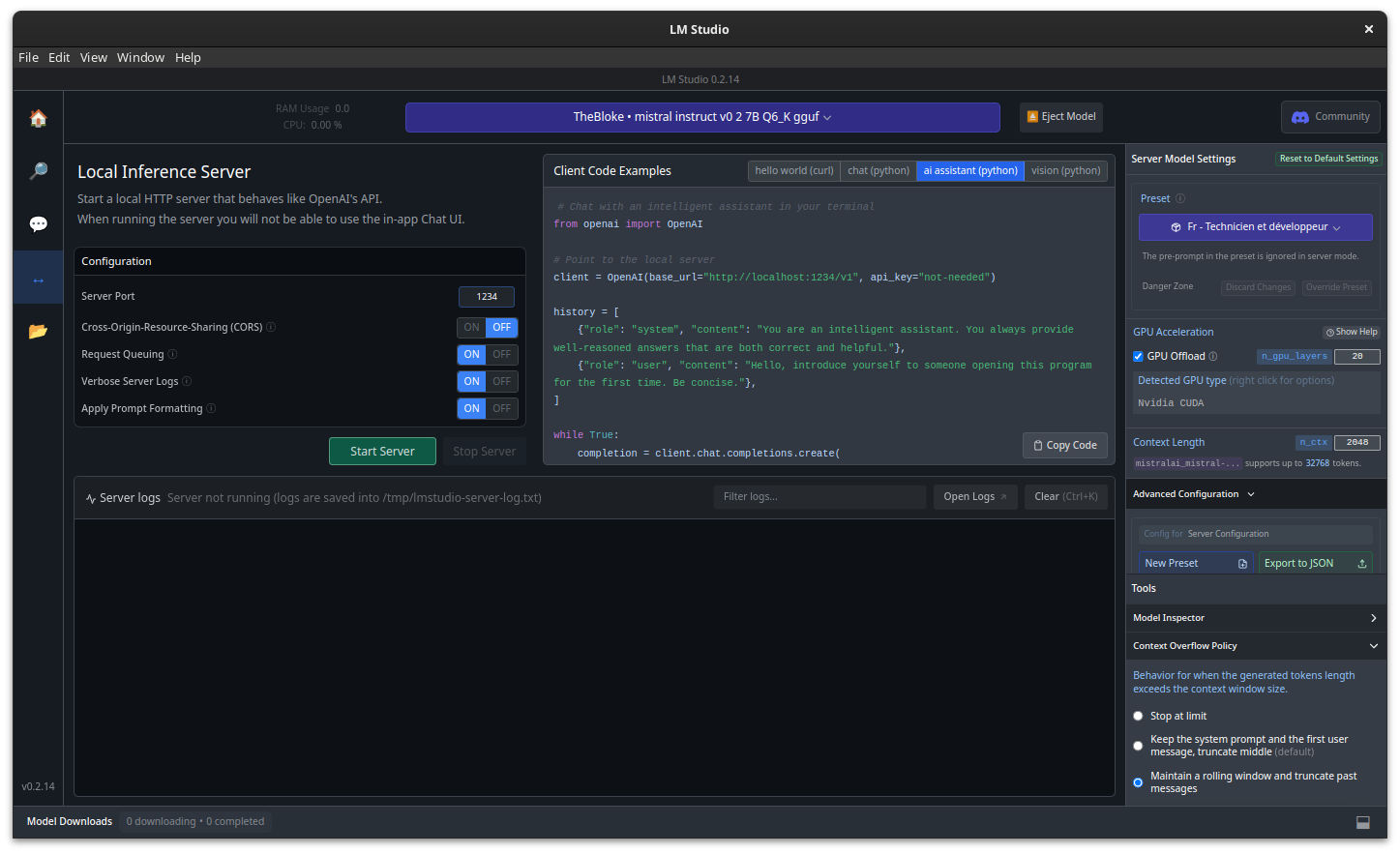
Bon sang, mais quelle idée de mettre une icône aussi foireuse !
Il suffit de lancer le serveur et nous voilà avec une API compatible OpenAI. Entendez par là que vous pouvez utiliser le package “openai” en Python (ou utiliser curl, mais on n’est pas des sauvages).
Donc, on se lance dans un délire !
Et si…
Et si, comme ça, mode bourrin, à 22 heure, devant la télé, le gamin qui dort… je me lançais dans un script qui appelle l’API locale, et que je traitais les réponses pour enregistrer les données dans des fichiers.
T’as sommeil ? Non…
Je sais que je vais me confronter à pas mal d’embuches. Parce que je suis habitué avec le temps. J’en ai testé des modèles, j’en ai bouffé des craquages à façonner mes requêtes pour avoir un prompt qui passe bien. Et je ne vous dis pas le nombre de fois où j’ai fait planter la machine en chargeant un peu trop fortement l’historique de conversation dans la VRAM.
Donc, je sais à quoi m’en tenir, et je sais très bien, avant même de commencer, que je vais devoir :
- ruser avec l’historique de conversation
- devoir traiter les résultats
- ne pas y aller trop fort, demander 10-20 produits par requête, sinon ça va foirer (non mais j’ai testé avec 100, ça fait n’importe quoi)
Allez, je me lance !
Rappel de ce que je veux faire
Le but est d’avoir un ou plusieurs fichier JSON qui contiennent des produits. Je veux m’en servir pour alimenter une base de données de test. J’ai juste besoin de ces champs:
name: qui est un nom de produitdescription: qui décrit le produittags: qui est une liste de tagcategories: pareil, une liste de catégories, moins verbeuse,price: nombre à virgule, un prix…
Je me fiche un peu de la cohérence et que les produits n’existent pas. J’ai besoin de données, c’est tout.
Et je les veux en français ! C’est tout le problème qui fait que je n’ai rien trouvé de viable sur le net.
Passons à Python
Bon, j’adore pipenv, donc :
mkdir -p ~/Projects/ML/product-generator
cd ~/Projects/ML/product-generator
pipenv install openai
Pour bien comprendre comment ça se passe, il faut faire un petit test.
from openai import OpenAI
API_URL="http://127.0.0.1:1234/v1" # LM Studio API
API_KEY="not-needed"
client = OpenAI(base_url=API_URL, api_key=API_KEY)
history = [
{
"role": "system",
"content": "Ici, une description claire pour donner une condition à l'IA",
},
{
"role": "user",
"content": "Là, une question à poser"
}
]
response = client.chat.completions.create(
model=MODEL_NAME, # this field is currently unused if you use LM Studio
messages=history, # pyright: ignore
temperature=0.7,
stream=False,
)
# on affiche le résultat
print(response)
# en fait c'est plutôt
print(response.choices[0].message.content)
Là, on a une prémisse de ce qu’il faut faire. Reste donc à bien formater le “prompt” et comprendre le rôle de l’historique.
Le rôle de l’historique et le problème de “taille”
Mais de quel historique il parle ?
On parle de l’historique de conversation. En fait, les modèles conversationnels font des réponses “one shot”, entendez par là qu’il ne gardent pas en mémoire ce que vous lui avez dit, et ce qu’il vous a répondu. Il faut lui rappeler tout ça à chaque fois que vous relancez un prompt. C’est un historique de conversation.
Rappelez-vous qu’un modèle n’est pas un logiciel, pas un service. Il est figé.
En général, les LLM ont deux modes. Il y a des modèles de “completion” (qui continuent un début de phrase), et des modèle “instructions” qui, eux, peuvent prendre en compte des contextes.
La liste history est donc un tableau qui représente la conversation avec le “bot”. C’est un “contexte” pour qu’il continue la conversation.
Et un contexte, c’est en général une liste de prompts. Ces prompts ont pour la plupart 3 rôles différents :
- “
system” pour donner un contexte initial (on lui donne en début de conversation et une seule fois), - “
user” qui correspond à vos messages, - et “
assistant” qui sont les réponses données par le modèle.
On doit bien les mettre dans l’ordre (contexte initial, puis questions et réponses dans l’ordre chronologique) afin d’avoir une logique.
Donc, si vous voulez créer une conversation, à chaque fois il faudra prendre la réponse du modèle, l’ajouter dans cette liste, ajouter une nouvelle phrase ou question venant de vous, et rappeler l’API.
Vous voyez le souci… si je veux générer des centaines de produits au format JSON, avec des descriptions, ça va être problématique…
Ça veut dire qu’à un moment donné, mon historique va être énorme. Et ma machine ne va pas supporter que je donne au modèle plusieurs miliers de lignes de texte générées.
Si je dois renvoyer les réponses au modèle pour qu’il évite les doublons, et qu’il “continue” à générer des produits au fur et à mesure :
- je vais taper dans la limite que supporte une requête HTTP
- je vais saturer la RAM / VRAM, qui doit déjà charger les 4 Go de modèle (avec 20 couches, pour avoir un peu de place)
Donc, il va falloir ruser… C’est tout le travail du “prompt engineering”. Notez que ce domaine est très mal compris par beaucoup de corps de métiers en informatique. Beaucoup pense que c’est juste “taper des prompts malins”, mais en réalité, quand on commence à pousser un peu dans le domaine, c’est une tâche qui peut s’avérer très complexe. Et dans notre cas, ça ne l’est pas tellement, pourtant il m’a fallu faire pas mal de tests pour que ça soit bon. Donc, je défends les “prompt engineer” pour ma part.
La ruse de sioux
Je me suis dit :
“Attend mais… on s’en fout de lui fournir les JSON, ou même la conversation. Parce que le contexte, je peux le contrôler moi même.
On va juste lui donner la liste de noms des produits qu’il a générés”.
Et oui, on va être clair et lui dire qu’on a déjà “ces produits”, c’est tout ! Et comme c’est une IA, que le “I” veut dire “Intelligence”, il ne devrait pas être trop débile.
Le bon prompt
Donc, en mode “chatbot” dans LM Studio, j’ai testé quelques prompts + contextes initiaux pour trouver la bonne formule, pour générer du JSON pas trop mauvais.
- Dans “
system”, je dois être très explicite. Je dois lui dire qu’il est un expert en développement, qu’il est francophone et ne répond qu’en français. Qu’il est capable de générer du JSON valide, et blablabla - dans ma question, je dois lui donner beaucoup de détails, et notamment le schéma JSON que je veux qu’il respecte. Le nombre de produits à générer (à partir de 20 il gueule un peu en disant qu’il va déborder, donc on se limite à 10 pour le moment)
Notons que le markdown est accepté, ce qui donne encore un peu plus de sens à nos prompts.
Donc, voilà ce que j’ai fait dans mon script :
SCHEMA = """
```json
[
{
"name": "string",
"description": "string",
"price": 0.0,
"categories": ["string"]
}, {...}
}
```
"""
NUM_PRODUCTS_PER_REQUEST = 5 # The number of products you want to generate
INIT_HISTORY = [
# the system role is used to set the language and the role of the model. We exxplicitly
# tell that the model must respond in French - change the message to your target language
{
"role": "system",
"content": (
"Tu es un développeur français et ne répond qu'en français. "
"Tu peux proposer des solutions à des problèmes de programmation "
"et générer du contenu technique."
),
},
# here we ask the model to generate a list of products in JSON format
# with the given schema
{
"role": "user",
"content": (
"J'ai besoin que tu me génères, en JSON, une liste de "
f"{NUM_PRODUCTS_PER_REQUEST} produits avec name, "
"description, price et categories. Le nom doit être pertinent et unique, "
"la description claire, et de 2 à 5 catégories. "
"Le contenu doit être en français. "
"Retourne un tableau d'objets JSON. "
"Le schema doit être conforme à : " + SCHEMA
),
},
]
Ces variables me servent de configuration. Ce n’est pas super joli, mais ça a le mérite de rester en haut de mon script.
Reste un sérieux souci… le JSON n’est pas forcément donné directement, il est souvent imbriqué dans du Markdown parce que le modèle est fait pour répondre avec de la mise en page.
Un modèle trop humain ?
Ou disons plutôt “trop orienté sur l’imitation d’un humain”.
Le modèle Mistral 7b est vraiment bien foutu, pour faire un chatbot. Il est franchement intéressant pour discuter. Mais moi je veux me servir du modèle pour générer de la donnée. Je n’ai pas envie de discuter avec lui.
On doit éliminer les phrases de gentillesse. Parce que voilà, il va vous répondre, de temps en temps, un truc du genre :
Voilà 5 nouveaux produits, j'espère que cette réponse vous convien !
```json
le contenu json ici
```
N'hésitez pas à me demander plus de trucs...
Mais parfois, il répond avec du JSON, directement, sans même un bonjour…
On a donc besoin de tenter de charger la réponse “telle quelle”, si ça plante on passe un une extraction Markdown. Je n’ai pas mieux pour le moment :
def extract_json_from_markdown(content):
""" Extract the JSON content from the response inside a markdown block """ ""
# The response is a string, there is a json inside "```" and "```", we extract it
# it is possible that the model starts the json with a newline, so we need to remove it
json_start = content.find("```") + 3
json_end = content.rfind("```")
json_content = content[json_start:json_end]
if json_content.startswith("json"):
json_content = json_content[4:]
try:
loaded = json.loads(json_content)
except Exception: # pyright: ignore pylint: disable=broad-except
logging.info("JSON content not found as Markdown")
return None
return loaded
def extract_json_from_content(content):
"""Extract the JSON content from the response"""
# if the response is not warp in brackets, add them
content = content.strip()
if not content.startswith("["):
content = f"[{content}]"
try:
json_content = json.loads(content)
except Exception: # pyright: ignore pylint: disable=broad-except
logging.info("JSON content not found as full response")
return None
return json_content
def extract_json_content(content):
"""Extract the JSON content from the response"""
content = content.strip()
loaded = extract_json_from_content(content)
if loaded is None:
loaded = extract_json_from_markdown(content)
if loaded is None:
logging.error("Error parsing JSON content, no content")
return None
# save known products name
KNOWN_PRODUCTS.extend([product["name"] for product in loaded])
return loaded
Vous remarquez que je stocke le nom des produits généré pour les redonner à manger au modèle afin de ne pas avoir de doublons.
On fait en sorte de “continuer”
Je vous passe les détails, vous verrez le code final dans le lien en bas de l’article, mais je sauve les JSON dans des fichiers numérotés. Et je me débrouille pour les charger au démarrage du script si besoin.
Passons ce détail, maintenant je veux gérer l’historique proprement. En résumé :
- si je suis sur la première itération, je demande ma liste de produit
- ensuite, si je “continue” la génération pour avoir d’autres produits, et bien je veux ajouter l’information qui donne la liste des produits que j’ai déjà
Donc, on se garde une variable “KNOWN_PRODUCTS” dans une globale bien dégueulasse, et on se génère une liste à la Markdown. Parce que le modèle comprend la “mise en forme”. Comme ça je peux lui dire que ne ne veut pas les produits que j’ai déjà stocké.
APPEND_PROMPT = """
J'ai déjà ces produits :
"""
KNOWN_PRODUCTS = []
def list_of_products():
"""Generate a list of products in markdown format"""
return APPEND_PROMPT.strip() + "\n".join([f"- {p}" for p in KNOWN_PRODUCTS])
Et je ponds une fonction pour générer le prompt dans le cas initial et le cas “continue” :
def create_completion(continuation=False):
"""Create a completion using the conversation history"""
# force a copy of the history
history = list(INIT_HISTORY)
# add the continuation prompt
if continuation:
history.append(
{
"role": "user",
"content": list_of_products(),
}
)
logging.info("History: %s", history)
return CLIENT.chat.completions.create(
model=MODEL_NAME, # this field is currently unused if you use LM Studio
messages=history, # pyright: ignore
temperature=0.7,
stream=False,
)
Cela va ajouter “j’ai déjà ces produits :” avec la liste des noms de produits déjà générés si je passe “True” en argument.
Un exemple de résultat ?
Allez… je vous montre un bout de fichier que me génère mon script (ne paniquez pas, je vous donne le lien du code en bas de l’article):
[
{
"name": "Samsung Galaxy S21 Ultra - Nouvelle G\u00e9n\u00e9ration",
"description": "Smartphone avec \u00e9cran OLED dynamic AMOLED 2X, processeur Exynos 2100 ou Snapdragon 888 et une batterie de 5000mAh.",
"price": 1299.99,
"categories": [
"Smartphones",
"Electronique"
]
},
{
"name": "Apple iPad Pro 12,9 pouces (5e g\u00e9n\u00e9ration)",
"description": "Tablette tactile dot\u00e9e d'un \u00e9cran Liquid Retina XDR avec M1 Chip et une batterie de 30.42 w-h.",
"price": 1119.0,
"categories": [
"Tablettes",
"Electronique"
]
},
{
"name": "Canon EOS R5 - Hybride RF Mount",
"description": "Appareil photo reflex num\u00e9rique \u00e0 plein format avec capteur CMOS de 45 Mpx et autofocus Dual Pixel.",
"price": 3899.0,
"categories": [
"Appareils photos",
"\u00c9lectronique"
]
},
{
"name": "Logitech MX Master 3 - Souris sans fil wireless",
"description": "Souris haut de gamme avec une ergonomie adapt\u00e9e \u00e0 la main, des boutons programmables et une batterie interne rechargeable.",
"price": 99.99,
"categories": [
"Souris informatique",
"\u00c9lectronique"
]
},
{
"name": "Dell XPS 15 - 9510",
"description": "Ordinateur de bureau portatif \u00e9quip\u00e9 d'un \u00e9cran OLED 15.6 inches, un processeur Intel Core i7 et une batterie de 86 Wh.",
"price": 2349.0,
"categories": [
"Ordinateurs portatifs",
"\u00c9lectronique"
]
}
]
Et j’en ai généré 1500, scindés en pleins de fichiers.
Ça a pris un peu de temps, soyons honnête. Ma machine est limitée (c’est un portable hein, donc les RTX sont bien bridée), et mon vieux coucou ne comprend pas les instructions AVX2 (donc, j’ai 24 Go de RAM, une RTX 3070, un corei7, mais je ne peux pas l’utiliser avec Mistral avec LM Studio…)
Mais clairement, Python ici est fabuleux. Ce script n’est pas un truc de prod, c’est un gadget qui me génère de la data. J’ai codé ce machin en 20 minutes environ.
Le code final
Bien entendu, je n’ai pas tout décrit dans cet article. Le code complet est dans un “gist” :
https://gist.github.com/metal3d/448da715534baf686c1fffc685483296
Le script génère des fichiers, sans écraser les anciens. Il sait relire les données déjà générées pour continuer la génération de JSON.
Ce n’est pas du grand art, je le sais. C’est codé à l’arrache, et ça mérite potentiellement de créer un vrai projet. Voir une interface graphique, etc.
Mais là, pour l’heure, j’ai bien tous mes fichiers générés.
Vous pouvez adapter le script, et notamment le prompt, pour changer la langue, forcer un domaine de produits, etc.
Amusez-vous !